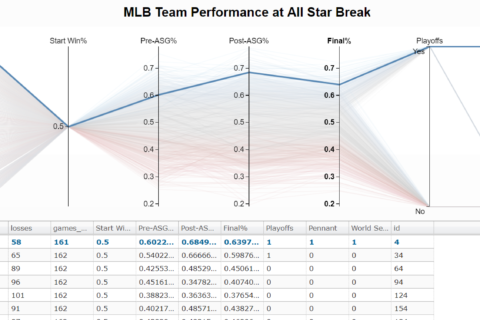
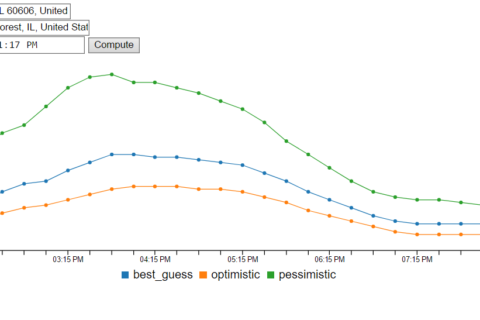
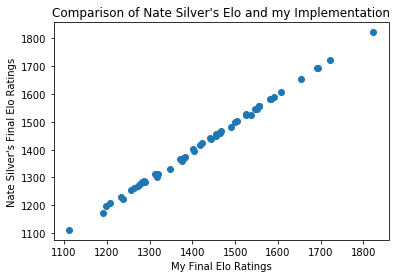
Automate Your Ring to Set your Ecobee to Away Mode!

It was really frustrating me how I had to first arm my alarm system and then go into each thermostat and set them to away. Then reverse the process when I got home. I thought Ecobee or Ring would have an official integration but it turns out they are competitors in the home automation space.… Read More Automate Your Ring to Set your Ecobee to Away Mode!