
Whenever I look for a new data source on the NFL or daily fantasy betting, I find a bunch of sad souls that don’t realize how easy it is to scrape data. People always want excel workbooks that already have all the data they need modeled up and ready to go but unfortunately they have to pay for that. In this post I hope to get you sold on web scraping and give you the tools and examples needed to get started with creating your own sports data “trading” firm.
Scrape Code for DraftKings or FanDuel
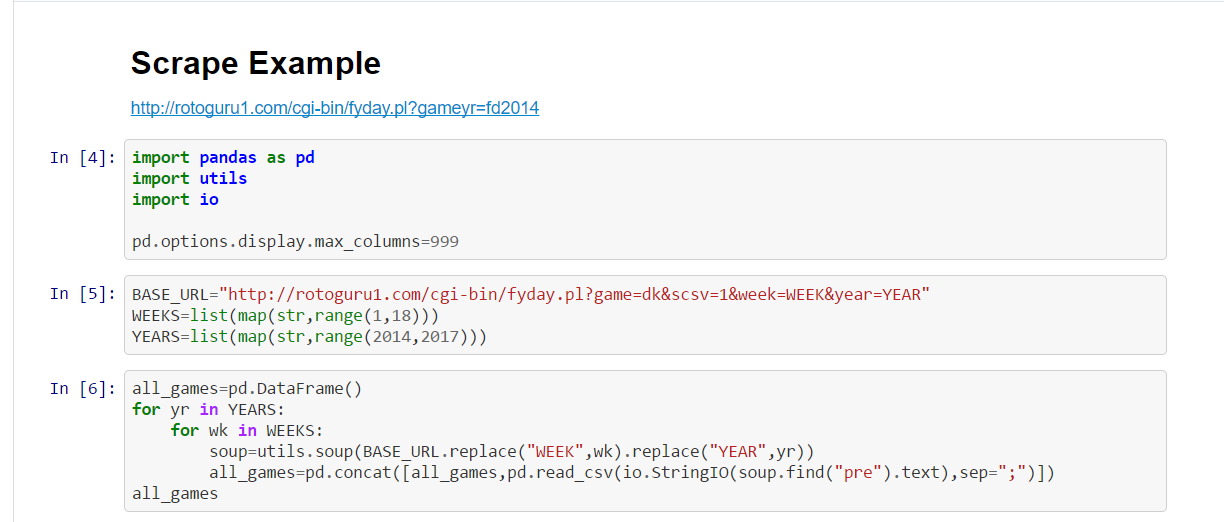
That’s it. A whopping 13 lines to scrape 20,546 draft kings’ player salaries and 51 pages and it took 20 minutes for me to do it start to finish — video tutorial here. From here you have a few options:
- Learn how to download any data you could ever want by watching the video and using my github link (4-10 hours to acquire the basic skills).
- Cheat and download the dataset (2 seconds)
- Use my sports data service Sports Data Direct (Receive immediate access; 34.95/month)
- Or you could just continue being a scavenger like homes over here
 Whatever you choose is fine but if you do choose the Han Solo route buy me a beer.
Whatever you choose is fine but if you do choose the Han Solo route buy me a beer.
[tiny_coffee]
Hi, I’m looking to scrape mlb baseball player salaries from 2008 until current in MYSQL. I did discover the Lahman database with mlb player salaries, but it’s incomplete. Will the draft kings code above be able to do this?
Thank you in advance.
Hi Lee. I need some clarification on your question. DraftKings salaries are not the actual salaries that players make but pretend salaries for daily fantasy sports. The Lahman database shows mlb salaries. I’d recommend you start with this. An already created salary dataset http://roadsidephotos.sabr.org/baseball/salaries.zip.
MLB is generally easier than other sports due to the stats junkies that are interested in baseball. Here’s more discussion https://www.baseball-reference.com/about/salary.shtml
Hi Person,
Ah, thanks for the clarification of the nature of DraftKings salaries and for the link for the already created salary dataset–This is useful. However, I’m looking to get salary information for MLB players for the years from 2008 until present aside from the Lahman database. While I was able to scrape salaries from the Lahman database from 2008 until present, the list is incomplete, as no salary information is included in Lahman’s list for many of the players I have in my database for those years.
I did locate the baseball reference website with salaries as well, but I believe that is the source that Lahman used to get salary information.
I’m also looking for biodata for mlb players from 2008 until present. I have located the “b-height”, and “birth_year” columns in the gameday database, but not weight.
Thank you in advance.
Regards,
Lee
Besides Lahman there is Cot’s Contracts if you didn’t see it yet. http://legacy.baseballprospectus.com/compensation/cots/ but it doesn’t have everything you need.
It won’t be for a while until I get around to baseball. If I ever do find a better source I’ll let you know!
Best of luck
Good afternoon,
Love this post as I stumbled upon RotoGuru1 a few weeks ago before I started playing DraftKings.
I’m trying to recreate your code in Python (using 3.6) and I’ve never used io or utils so I’m trying it by using requests and BeautifulSoup.
I can scrape the page using the “pre” tags and get the ouput I want but BeautifulSoup is returning a ResultSet instead of a list. Any idea what I could do?
I would love to save this as a list and convert it to a DataFrame for analysis and data cleaning later on.
Hi Brian
Thanks for reading!
You need to use
soup.find("pre").textThe .text turns the ResultSet into text. io is a core library including with Python 3.6 link but you parse it by creating your own csv parser without io and pandas. Just split on lines “\n” and the delimiter “;”.
That worked perfectly. I imported Pandas and used the trick to convert the screen block into a file using io.StringIO and saving it as a variable. I passed that variable to pd.read_csv and it worked.
I’m honestly shocked that more people haven’t seen your video. Most of the videos I’ve seen on YouTube that discuss creating Lineup Optimizers and getting DFS data show people copy and pasting it from different sites… that is absolutely nuts. I’m going to be spending some time now practicing how to clean this and add new fields, like a playerID column.
I’m very appreciate for this work you posted and for your response. I’m going to be reading more of your content.
Thanks! I agree. I’m considering making a course to show people how to do a lot of the data munging and scraping needed for sports data.
Also, take a look at my other blog https://www.blog.sportsdatadirect.com/ if you haven’t seen it yet. I do daily fantasy sport recap articles with a ton of analysis as well as sell sports data.
Hi – pretty impressive stuff. I have a quick question. I am using python 3.7 and every time I try to use the utils function I receive the following error.
module ‘utils’ has no attribute ‘soup’
The code I’m trying to write is soup=utils.soup(BASE_URL.replace(“WEEK”,wk).replace(“YEAR”,yr))
Any help would be much appreciated. Thanks.
Sorry about that, utils is not a standard library. In the video I used some of my own private libraries. You can use the notebook here https://github.com/rogerfitz/tutorials/blob/master/draft-kings-history-scrape/roto-guru.ipynb and make sure you copy the utils.py into the same folder as the notebook (here is the git repo https://github.com/rogerfitz/tutorials/tree/master/draft-kings-history-scrape)
Thanks! I’ll give that a try.
Hi,
Awesome post! I’m just wondering how often you update the weekly data. Do you publish the salary data (without points) prior to the upcoming week?
Hi sorry for late reply, I don’t check this blog often but if you email support@sportsdatadirect.com I’m much quicker.
Yes I publish the salary data ahead of time. It is loaded by Wednesday afternoon each week during the NFL regular season.
Tried to go to http://sportsdatadirect.com and it says it isn’t secure, both edge and chrome send me to other websites, etc to download extensions, etc.
Hi Thanks for the comment. I need to take down those links. I’ve since closed down sportsdatadirect.com and someone else has purchased the domain